
TESTS/secret.wav in Discord.

As you can see, RIFF files are made up of chunks. Each chunk has a ChunkSize (uint32), and ChunkID (char[4]). We can represent them as a C++ struct like so:
Next, we see that the RIFF file is one large “main” chunk with 3 new members: Format (char[4]), “fmt” SubChunk, “data” SubChunk. Since “main” chunk is also a chunk, we can use inheritance to make our lives easier:
Next we need to implement struct FormatChunk and struct DataChunk. Note, both of them are chunks, so they need to extend struct Chunk.
According to soundfile.sapp.org/, this structure for the wave file format would be perfect. However, actual wave files have many more subchunks, such as “bext”, “iXML”, etc. Wikipedia. Therefore, the starter code for the wave parser has a struct MiscChunk which is structually identical to the struct DataChunk. Therefore, the struct MainChunk, struct MiscChunk, and struct DataChunk look like this:
Nice! Now we just need to make sure that each struct has a load() and write() method.
C++ has a very easy way to open files: std::fstream. std::ifstream opens a file, and you can read just like std::cin. std::ofstream opens a file, and you can write to it just like std::cout.
This example takes in a file called "input_file.txt", and copies it into "output_file.txt".
However, this example is inaccurate because it does not account for files without a line break at the end. This would suffice for text files, but for binary files where every bit matters, this is unacceptable.
Plus, fstream may convert between different text encodings for different characters between operating systems. Once again, for text, this doesn’t really matter. But for binary data where every bit matters, consistency is crucial.
"\r\n" or 0x0D0A.
"\n" or 0x0A.
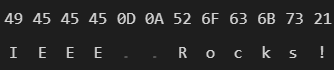
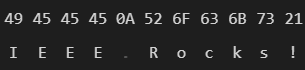
Because of this, we use fstream in binary mode. That way, no characters are translated/converted without our permission.
This is a much better example: